
# 03-机器学习vs深度学习
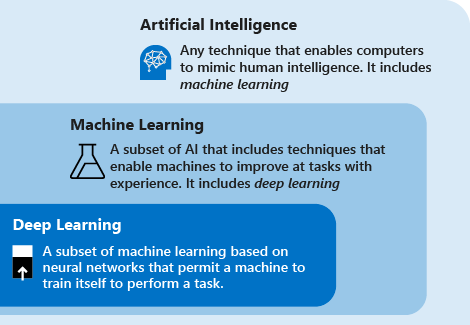
- 人工智能 (AI) 是使机器能够模拟人类智能的技术。 其中包括机器学习
- 机器学习是人工智能的子集,它采用可让机器凭借经验在任务中做出改善的技术(例如深度学习)。 学习过程基于以下步骤:
- 将数据馈送到算法中。 (在此步骤中,可向模型提供更多信息,例如,通过执行特征提取。)
- 使用此数据训练模型。
- 测试并部署模型。
- 使用部署的模型执行自动化预测任务。 (换言之,调用并使用部署的模型来接收模型返回的预测。)
- 深度学习是机器学习的子集,它基于人工神经网络。 学习过程之所以是深度性的,是因为人工神经网络的结构由多个输入、输出和隐藏层构成。 每个层包含的单元可将输入数据转换为信息,供下一层用于特定的预测任务。 得益于这种结构,机器可以通过自身的数据处理进行学习。
# 机器学习介绍
机器学习从数据中总结模型,而数据表示的经验可以包含不同的信息形态,其中的一个关键的信息,是关于模型表现的反馈信息。有的数据中包含了模型应该输出的值,有的数据则完全没有这一类信息,还有的数据中包含的是对模型表现的打分。不同的反馈信息导致我们需要用不同的技术进行处理,因此按照反馈信息的不同,机器学习经典划分为三大类:
- 监督学习:处理包含有模型正确输出值的数据,即有标记数据。例如图像识别数据中,每一张图像都有相应分类标记。
- 强化学习:处理的数据仅包含有模型打分值,而不知道模型到底应该输出什么,因此只能靠算法去不断的探索,寻找打分值最高的模型输出。例如围棋游戏,缺乏每一步走棋的最佳指导,只能通过最终的输赢作为打分,自主探索寻找最佳模型。
- 无监督学习:数据中完全没有关于模型输出好坏的客观评估。这时通常会人为的设置某种学习目标,以开展学习,例如把256维人脸照片压缩到4维,此时并没有任何关于这4维应该如何的信息,一种做法是使得这4维能够还原出256维的人脸,这就是一种人为设定的目标。这种还原自身信息的做法也叫自监督学习,虽然名称中有“监督”,其实是一类借用监督技术的无监督学习。
如果按任务类型来说,分为:
- 聚类
- 回归
- 分类
# 机器学习常见的算法
回归算法:试图采用对误差的衡量来探索变量之间的关系的一类算法。
包括最小二乘法、逻辑回归、逐步式回归、多元自适应回归样条、本地三点平滑估计等。本质上线性回归处理的是数值问题,最后预测的结果是数字,如预测房价,而逻辑回归属于分类算法,预测结果是离散的分类,如判断邮件是否为垃圾邮件等。
决策树算法
根据数据的属性采用树状结构建立决策模型,常用来解决分类和回归问题。包括分类及回归树、ID3、C4.5、随机森林、多元自适应回归样条(MARS)以及梯度推进机(GBM)等.
贝叶斯方法
基于贝叶斯定理,主要解决分类和回归问题。包括朴素贝叶斯算法、平均单依赖估计等。
聚类算法
通常按中心点或者分层的方式对输入数据进行归并,简单来说就是计算种群中的距离,根据距离的远近将数据划分为多个种群。试图找到数据的内在结构,以便按照最大的共同点将数据进行归类.
# 深度学习与机器学习的技术
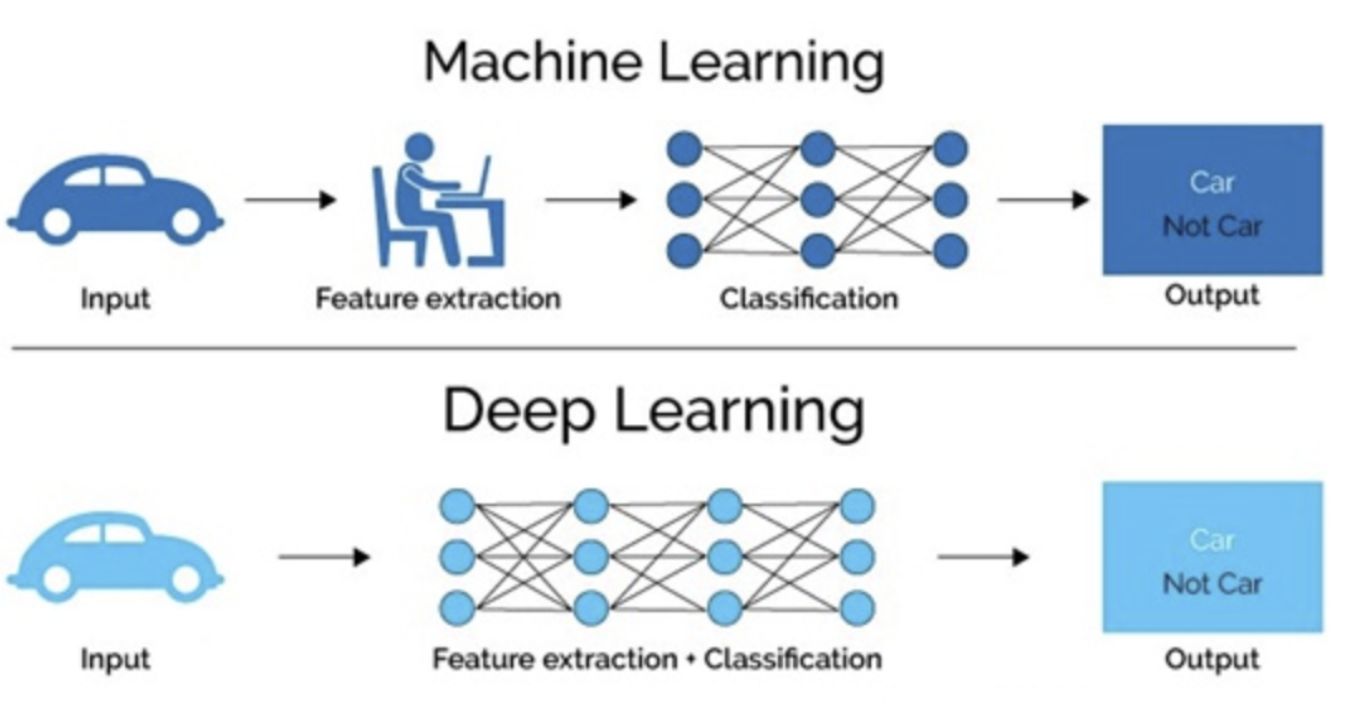
获得机器学习和深度学习的概述后,接下来让我们比较这两种技术。 在机器学习中,需要告知算法如何使用更多信息做出准确的预测(例如,通过执行特征提取)。 在深度学习中,得益于人工神经网络结构,算法可以了解如何通过自身的数据处理做出准确预测。
下表更详细地比较了这两种技术:
| 所有机器学习 | 仅限深度学习 | |
|---|---|---|
| 数据点数 | 可以使用少量的数据做出预测。 | 需要使用大量的训练数据做出预测。 |
| 硬件依赖项 | 可在低端机器上工作。 不需要大量的计算能力。 | 依赖于高端机器。 本身就能执行大量的矩阵乘法运算。 GPU 可以有效地优化这些运算。 |
| 特征化过程 | 需要可准确识别且由用户创建的特征。 | 从数据中习得高级特征,并自行创建新的特征。 |
| 学习方法 | 将学习过程划分为较小的步骤。 然后,将每个步骤的结果合并成一个输出。 | 通过端到端地解决问题来完成学习过程。 |
| 执行时间 | 花费几秒到几小时的相对较少时间进行训练。 | 通常需要很长的时间才能完成训练,因为深度学习算法涉及到许多层。 |
| 输出 | 输出通常是一个数值,例如评分或分类。 | 输出可以采用多种格式,例如文本、评分或声音 |
# 链接
Apache License 2.0 | Copyright © 2022 by xueliang.wu 苏ICP备15016087号