
# 15. Milvus介绍
Milvus是最近流行的云原生的向量数据库。如果想了解Milvus,需要对向量数据库和向量有一些基本的了解。可以通过文章腾讯云向量数据库 (opens new window)来熟悉什么是向量数据库。
几个概念:
- 什么是向量?
向量是指在数学和物理中用来表示大小和方向的量。它由一组有序的数值组成,这些数值代表了向量在每个坐标轴上的分量。
- 什么是向量检索?
向量检索是一种基于向量空间模型的信息检索方法。将非结构化的数据表示为向量存入向量数据库,向量检索通过计算查询向量与数据库中存储的向量的相似度来找到目标向量。
- 向量数据库主要做什么?
向量数据库的主要作用是存储和处理向量数据,并提供高效的向量检索功能。最核心是相似度搜索,通过计算一个向量与其他所有向量之间的距离来找到最相似的向量(最相似的知识或内容)。
整个2023年,最受瞩目的科技产品无疑是ChatGPT。随着ChatGPT的火爆,大模型推理也引发了大家对向量数据库的关注。那为什么大模型和向量数据库有关系呢?通过文章一文全面了解向量数据库的基本概念、原理、算法、选型 (opens new window)和我们对大模型的了解,大模型推理(回答问题)主要基于学习的数据,而学习的数据有完整性、时效性、专业性等各种缺陷,因而直接用大模型回答问题,问答感觉可以,但是应用到真是的客户场景,回经常发现大模型回答不正确。基于RAG等方法理论,我们可以通过数据预处理、向量检索、提示工程等步骤有效提升大模型的推理质量。
经典场景:
当我们有一份文档需要大模型,比如GPT处理时,例如这份文档是客服培训资料或者操作手册,我们可以先将这份文档的所有内容转化成向量(这个过程称之为 Vector Embedding),然后当用户提出相关问题时,我们将用户的搜索内容转换成向量,然后在数据库中搜索最相似的向量,匹配最相似的几个上下文,最后将上下文返回给GPT。这样不仅可以大大减少大模型的计算量,从而提高响应速度,更重要的是降低成本,并绕过 GPT 的 tokens 限制。
大模型的流程图:
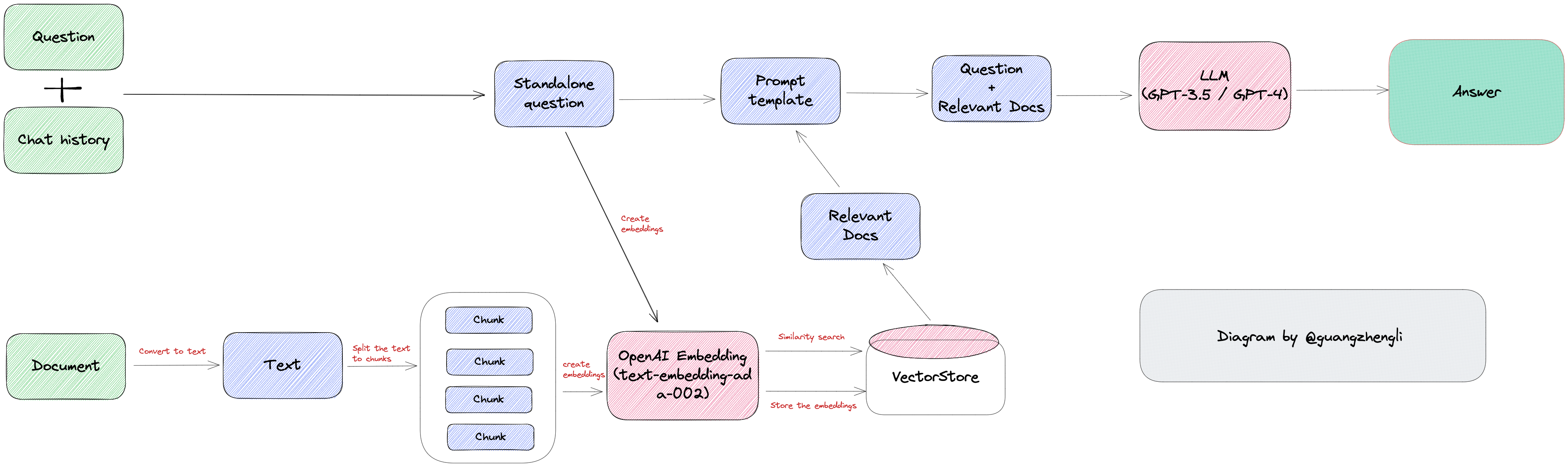
大模型能够回答较为普世的问题,但是若要服务于垂直专业领域,会存在知识深度、知识准确度和时效性不足的问题,比如:医疗或法律行业智能服务要求知识深度和准确度比较高,那么企业构建垂直领域智能服务?目前有两种模式:
- 基于大模型的Fine Tune方式构建垂直领域的智能服务,需要较大的综合投入成本和较低的更新频率,适用性不是很高,并适用于所有行业或企业。
- 通过构建企业自有的知识资产,结合大模型和向量数据库来搭建垂直领域的深度服务,本质是使用知识库进行提示工程(Prompt Engineering)。
# Milvus向量数据库
Milvus向量数据库可以查看官方文档Milvus (opens new window)下载和学习。习惯看中文的,可以看Milvus中文文档 (opens new window)
# Mivlus快速学习
- 安装Milvus 安装milvus有很多方式,大家可以参考官方地址。下边是单机docker的安装方式,方便大家复制。
version: '3.5'
services:
etcd:
container_name: milvus-etcd
image: quay.io/coreos/etcd:v3.5.5
environment:
- ETCD_AUTO_COMPACTION_MODE=revision
- ETCD_AUTO_COMPACTION_RETENTION=1000
- ETCD_QUOTA_BACKEND_BYTES=4294967296
- ETCD_SNAPSHOT_COUNT=50000
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/etcd:/etcd
command: etcd -advertise-client-urls=http://127.0.0.1:2379 -listen-client-urls http://0.0.0.0:2379 --data-dir /etcd
healthcheck:
test: ["CMD", "etcdctl", "endpoint", "health"]
interval: 30s
timeout: 20s
retries: 3
minio:
container_name: milvus-minio
image: minio/minio:RELEASE.2023-03-20T20-16-18Z
environment:
MINIO_ACCESS_KEY: minioadmin
MINIO_SECRET_KEY: minioadmin
ports:
- "19001:9001"
- "19000:9000"
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/minio:/minio_data
command: minio server /minio_data --console-address ":9001"
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9000/minio/health/live"]
interval: 30s
timeout: 20s
retries: 3
standalone:
container_name: milvus-standalone
image: milvusdb/milvus:v2.3.3
command: ["milvus", "run", "standalone"]
security_opt:
- seccomp:unconfined
environment:
ETCD_ENDPOINTS: etcd:2379
MINIO_ADDRESS: minio:9000
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/milvus:/var/lib/milvus
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9091/healthz"]
interval: 30s
start_period: 90s
timeout: 20s
retries: 3
ports:
- "19530:19530"
- "19091:9091"
depends_on:
- "etcd"
- "minio"
networks:
default:
name: milvus
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
启动:
export DOCKER_VOLUME_DIRECTORY=/data/xueliang.wu/docker_data/milvus
#启动
docker-compose -f docker-compose.yml up -d
#停止
docker-compose -f docker-compose.yml down
2
3
4
5
6
7
2.Milvus基本的概念和操作
方便跟熟悉的关系数据库对比,对照关系如下:
| Milvus 向量数据库 | 关系型数据库 |
|---|---|
| Collection | 表 |
| Entity | 行 |
| Field | 表字段 |
很多类似的术语,大家亲自体验一下就很快熟悉了。下边一个是向量数据库创建collection、删除collection、插入数据,检索数据、创建index的列子。
import time
import numpy as np
from pymilvus import (
connections,
utility,
FieldSchema, CollectionSchema, DataType,
Collection,
)
def create_connection(host='localhost', port='19530'):
print("start connecting to Milvus")
connections.connect("default", host=host, port=port)
def create_collection():
has = utility.has_collection("hello_milvus")
print("collection hello_milvus:{}".format(has))
if has:
print("collection has existed")
return
num_entities = 3000
dim = 8
fields = [
FieldSchema(name="pk", dtype=DataType.VARCHAR, is_primary=True, auto_id=False, max_length=100),
FieldSchema(name="random", dtype=DataType.DOUBLE),
FieldSchema(name="embeddings", dtype=DataType.FLOAT_VECTOR, dim=dim)
]
schema = CollectionSchema(fields, "hello_milvus is the simplest demo to introduce the APIs")
hello_milvus = Collection("hello_milvus", schema, consistency_level="Strong")
print("insert data to collection:hello_milvus")
rng = np.random.default_rng(seed=19530)
entities = [
# provide the pk field because `auto_id` is set to False
[str(i) for i in range(num_entities)],
rng.random(num_entities).tolist(), # field random, only supports list
rng.random((num_entities, dim)), # field embeddings, supports numpy.ndarray and list
]
insert_result = hello_milvus.insert(entities)
hello_milvus.flush()
print("isnert result:{},rows:{}".format(insert_result, hello_milvus.num_entities))
def create_index():
print("Start Creating index IVF_FLAT")
index = {
"index_type": "IVF_FLAT",
"metric_type": "L2",
"params": {"nlist": 128},
}
hello_milvus = Collection("hello_milvus")
ret = hello_milvus.has_index()
if ret:
hello_milvus.create_index("embeddings", index)
else:
print("exist index")
def search():
print("Start querying with `random > 0.5`")
start_time = time.time()
hello_milvus = Collection("hello_milvus")
result = hello_milvus.query(expr="random > 0.5", output_fields=["random", "embeddings"])
end_time = time.time()
print("user time:{}", end_time - start_time)
for hit in result:
print(f"hit: {hit}, random field: {hit.get('random')}")
def drop_collection():
print("drop collection:hello_milvus")
utility.drop_collection("hello_milvus")
if __name__ == '__main__':
# 1. connect to Milvus
create_connection('10.12.8.30', '19530')
# 2. create one collection
create_collection()
# 3. create index
create_index()
# 4 search
search()
# 5 drop
drop_collection()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
引用